function go(maxColumnsCount) {
var results = [];
for (var er = 0; er < errors.length; er++) {
if (!results.length) {
// первоначальное заполнение
for (var c = 0; c < colcount; c++) {
results.push([c]);
}
} else {
var newResults = [];
for (var r = 0; r < results.length; r++) {
// проверяем существующие кандидаты на валидность для следующей ошибки
if (isUnique(results[r], newResults) && checkCollisions(results[r], er)) {
newResults.push(results[r]);
} else {
for (var i = 0; i < colcount; i++) {
var candidateresult = results[r].slice();
if (candidateresult.length < maxColumnsCount && candidateresult.indexOf(i) < 0) {
candidateresult.push(i);
if (isUnique(candidateresult, newResults) && checkCollisions(candidateresult, er)) {
newResults.push(candidateresult);
}
}
}
}
}
if (newResults.length) {
results = newResults;
} else {
logIt("error cannot be indentified [" + er + "]:" + errors[er]["name"]);
}
}
//logIt(JSON.stringify(results));
}
logIt(JSON.stringify(results));
}
function checkCollisions(res, row) {
var values = [];
for (var r = 0; r < res.length; r++) {
values.push(errors[row]["f"][res[r]]);
}
for (var cr = 0; cr < row; cr++) {
var same = true;
for (var v = 0; v < values.length; v++) {
if (values[v] != errors[cr]["f"][res[v]]) {
same = false;
break;
}
}
if (same) return false;
}
return true;
}
function isUnique(candidate, results) {
candidate.sort(function(a, b) {
return a - b
});
for (var r = 0; r < results.length; r++) {
if (candidate.length == results[r].length) {
var same = true;
for (var c = 0; c < candidate.length; c++) {
if (candidate[c] != results[r][c]) {
same = false;
break;
}
}
if (same) {
return false;
}
}
}
return true;
}
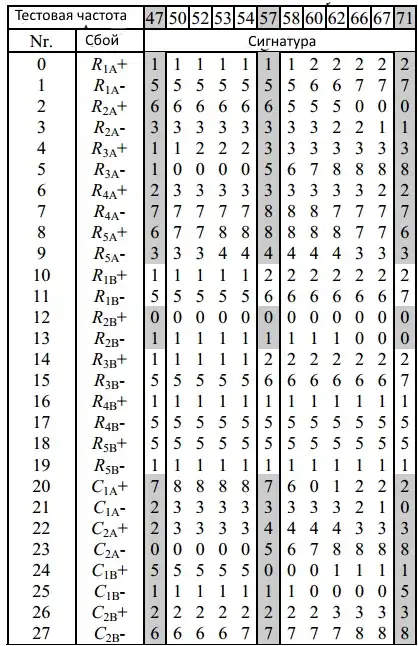
var errors = [{
"name": "R1A+",
"f": [1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2]
}, {
"name": "R1A-",
"f": [5, 5, 5, 5, 5, 5, 5, 6, 6, 7, 7, 7]
}, {
"name": "R2A+",
"f": [6, 6, 6, 6, 6, 6, 5, 5, 5, 0, 0, 0]
}, {
"name": "R2A-",
"f": [3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 1, 1]
}, {
"name": "R3A+",
"f": [1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3]
}, {
"name": "R3A-",
"f": [1, 0, 0, 0, 0, 5, 6, 7, 8, 8, 8, 8]
}, {
"name": "R4A+",
"f": [2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2]
}, {
"name": "R4A-",
"f": [7, 7, 7, 7, 7, 8, 8, 8, 7, 7, 7, 7]
}, {
"name": "R5A+",
"f": [6, 7, 7, 8, 8, 8, 8, 8, 8, 7, 7, 6]
}, {
"name": "R5A-",
"f": [3, 3, 3, 4, 4, 4, 4, 4, 4, 3, 3, 3]
}, {
"name": "R1B+",
"f": [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2]
}, {
"name": "R1B-",
"f": [5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 7]
}, {
"name": "R2B+",
"f": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}, {
"name": "R2B-",
"f": [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
}, {
"name": "R3B+",
"f": [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2]
}, {
"name": "R3B-",
"f": [5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 7]
}, {
"name": "R4B+",
"f": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}, {
"name": "R4B-",
"f": [5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
}, {
"name": "R5B+",
"f": [5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
}, {
"name": "R5B-",
"f": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}, {
"name": "C1A+",
"f": [7, 8, 8, 8, 8, 7, 6, 0, 1, 2, 2, 2]
}, {
"name": "C1A-",
"f": [2, 3, 3, 3, 3, 3, 3, 3, 3, 2, 1, 0]
}, {
"name": "C2A+",
"f": [2, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 3]
}, {
"name": "C2A-",
"f": [0, 0, 0, 0, 0, 5, 6, 7, 8, 8, 8, 8]
}, {
"name": "C1B+",
"f": [5, 5, 5, 5, 5, 0, 0, 0, 1, 1, 1, 1]
}, {
"name": "C1B-",
"f": [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 5]
}, {
"name": "C2B+",
"f": [2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3]
}, {
"name": "C2B-",
"f": [6, 6, 6, 6, 7, 7, 7, 7, 7, 8, 8, 8]
}];
var colcount = errors[0]["f"].length;
document.getElementById("go").addEventListener("click", function() {
go(parseInt(document.getElementById("maxCol").value) || 3);
});
document.getElementById("clear").addEventListener("click", function() {
document.getElementById("log").value = "";
});
function logIt(msg) {
var memo = document.getElementById("log");
memo.value = memo.value + "\n" + msg;
}